import urllib.request
import xarray as xr
import netCDF4 as nc
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.colors import LinearSegmentedColormap
import warnings
warnings.filterwarnings('ignore')Time series of chlorophyll data from different sensors
Great Lakes color producing agents (CPA) are derived from two different sensors.
As an example, we are going to plot time-series of mean chlorophyll a concentration from different sensors from 2002 to 2023. We are going to download MODIS data (2002-2017) and VIIRS data (2018-2023).
First, let’s load all the packages needed:
##Get Lake Erie Monthly Average MODIS data
Go to ERDDAP to find the name of the dataset for dailly MODIS data: LE_CHL_MODIS_Daily
You should always examine the dataset in ERDDAP to check the date range, names of the variables and dataset ID, to make sure your griddap calls are correct:
https://apps.glerl.noaa.gov/erddap/griddap/LE_CHL_MODIS_Daily.graph
- let’s download data for Lake Erie:
# in Python code replace coastwatch.glerl.noaa.gov with apps.glerl.noaa.gov
url='https://apps.glerl.noaa.gov/erddap/griddap/LE_CHL_MODIS_Daily.nc?chlorophyll%5B(2002-08-07T19:05:00Z):1:(2017-10-22T18:00:00Z)%5D%5B(41.0051550293714):1:(42.9950003885447)%5D%5B(-83.4950003885448):1:(-78.505388156246)%5D'urllib.request.urlretrieve(url, "e_chl_modis.nc")- let’s use xarray to extract the data from the downloaded file:
e_m_ds = xr.open_dataset('e_chl_modis.nc',decode_cf=False)e_m_ds.coordse_m_ds.time.valuese_m_ds.data_varse_m_ds.chlorophyll.shapeThe downloaded data contains only one variable: chlorophyll.
- Extract the dates corresponding to the data of each day:
e_m_dates=nc.num2date(e_m_ds.time,e_m_ds.time.units, only_use_cftime_datetimes=False,
only_use_python_datetimes=True )
e_m_dates
#e_m_ds.timee_m_ds.chlorophyll.attrs['_FillValue']# In chlorophyll array, replace -999 with nan
nan_e_m_ds_chlorophyll = e_m_ds.chlorophyll.where(e_m_ds.chlorophyll.values != e_m_ds.chlorophyll.attrs['_FillValue'])
#print(nan_e_m_ds_chlorophyll[0,100,:] )
print(nan_e_m_ds_chlorophyll)- Compute the monthly mean over the region data :
# Create list of string contains 'year month day hours minutes seconds'
d_list = []
[ d_list.append(dt.strftime("%Y %m %d %H %M %S")) for dt in e_m_dates]
#print(min(d_list))
#print(max(d_list))
mn = '08'
yr = '2009'
i_list = []
for n, d in enumerate(d_list):
d_t = d.split()
if d_t[0] == yr and d_t[1] == mn:
# print( n, d_t)
i_list.append(n) # get all index of data for yr and mn
#print(n, d)
#print(i_list)
# axis=0 is time line
chl_avg_img = nan_e_m_ds_chlorophyll.values[i_list[0]:i_list[-1]].mean(axis=0)
print(chl_avg_img.shape)# find max and min value in chl_avg_img
print(np.nanmin(chl_avg_img))
print(np.nanmax(chl_avg_img))# number of colors
levs = np.arange(np.nanmin(chl_avg_img), np.nanmax(chl_avg_img), 0.3)
len(levs)# init a color list
jet=["blue", "#007FFF", "cyan","#7FFF7F", "yellow", "#FF7F00", "red", "#7F0000"]
cm = LinearSegmentedColormap.from_list('my_jet', jet, N=len(levs))-Draw the image of monthly mean
plt.subplots(figsize=(10, 5))
#plot image chl_avg_img
plt.contourf(e_m_ds.longitude, e_m_ds.latitude, chl_avg_img, levs,cmap=cm)
#plot the color scale
plt.colorbar()
#example of how to add points to the map
#plt.scatter(np.linspace(-82,-80.5,num=4),np.repeat(42,4),c='black')
#example of how to add a contour line
#step = np.arange(1,100, 10)
#plt.contour(e_m_ds.longitude, e_m_ds.latitude, chl_avg_img,levels=step,linewidths=1)
#plot title
plt.title("Lake Erie Average CHL - " + yr + '-' + mn)
plt.show()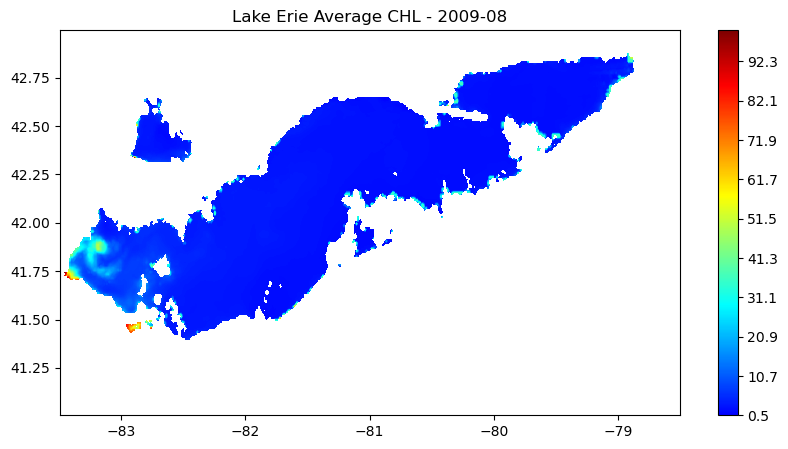
- Compute the Lake Erie chlorophyll monthly mean from 2002 to 2017
d_list = []
[ d_list.append(dt.strftime("%Y %m %d %H %M %S")) for dt in e_m_dates]
#print(min(d_list))
#print(max(d_list))
m_yr_list = []
[ m_yr_list.append(str(dt.year)) for dt in e_m_dates if str(dt.year) not in m_yr_list ]
print(m_yr_list)
print(len(m_yr_list))
mn_list = ['01','02','03','04','05','06','07','08','09','10','11','12']
m_chl_avg_list = []
for yr in m_yr_list:
for mn in mn_list:
i_list = []
for n, d in enumerate(d_list):
d_t = d.split()
#print(type(yr), type(mn), d_t)
if d_t[0] == yr and d_t[1] == mn:
#print( n, d_t)
i_list.append(n) # get all index of data for yr and mn
#print(i_list, 'aaa')
if i_list:
#print('bbb')
# axis=0 is time line
m_chl_avg = np.nanmean(nan_e_m_ds_chlorophyll.values[i_list[0]:i_list[-1]],axis=(0,1,2))
#print(i_list)
#print('ccc', chl_avg)
else:
m_chl_avg = np.NAN
#print(yr, mn, chl_avg)
m_chl_avg_list.append(m_chl_avg) # add each month mean data into list
print(len(m_chl_avg_list))
print(m_chl_avg_list)x = np.linspace(2002, 2018,num=192) # contains data from 2002 to 2017 (not include 2018)
#units = e_m_ds.chlorophyll.attrs['units']
plt.figure(figsize=(12,5))
plt.plot(x,m_chl_avg_list,label='MODIS CHL',c='red',marker='.',linestyle='-')
plt.ylabel('Chl-a (mg/m^3)')
plt.title("Lake Erie Monthly Average CHL " + m_yr_list[0] + '-' + m_yr_list[-1])
plt.legend()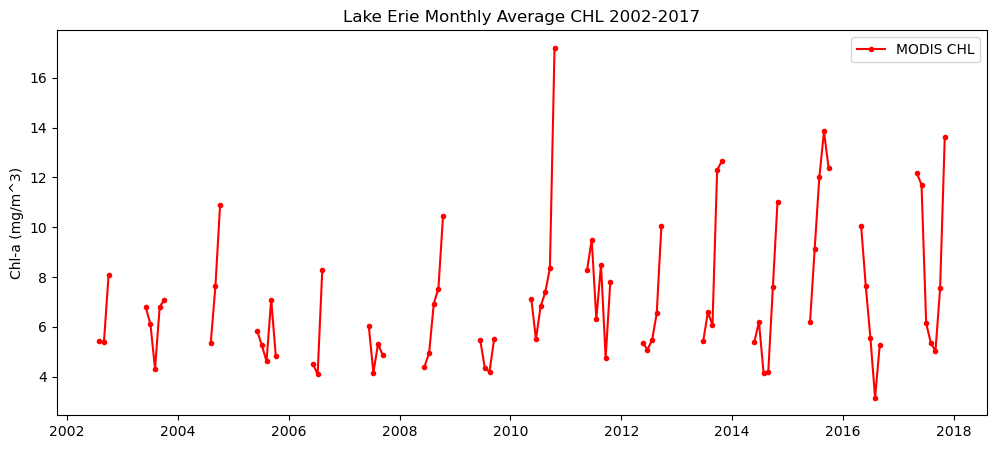
Get Lake Erie Dailly Average VIIRS data
url2='https://apps.glerl.noaa.gov/erddap/griddap/LE_CHL_VIIRS_Daily.nc?Chlorophyll%5B(2023-01-04T18:47:05Z):1:(2023-12-28T18:32:33Z)%5D%5B(41.2690208353804):1:(43.017997272827)%5D%5B(-83.6574899492178):1:(-78.4429490894234)%5D'
urllib.request.urlretrieve(url2, "e_viirs_chl.nc")e_v_ds = xr.open_dataset('e_viirs_chl.nc',decode_cf=False)print(e_v_ds)nan_e_v_ds_chlorophyll = e_v_ds.Chlorophyll.where(e_v_ds.Chlorophyll.values != e_v_ds.Chlorophyll.attrs['_FillValue'])
v_chl_avg = np.nanmean(nan_e_v_ds_chlorophyll,axis=(1,2))
#print(v_chl_avg)
#print(len(v_chl_avg))e_v_dates=nc.num2date(e_v_ds.time,e_v_ds.time.units, only_use_cftime_datetimes=False,
only_use_python_datetimes=True )
e_v_datesv_chl_avg = np.nanmean(nan_e_v_ds_chlorophyll.values,axis=(1,2))
v_chl_avgplt.figure(figsize=(12,5))
plt.plot(e_v_dates,v_chl_avg,label='VIIRS CHL',c='red',marker='.',linestyle='-')
plt.ylabel('Chl-a (mg/m^3)')
plt.title("Lake Erie Daily Average CHL - 2023")
plt.legend()
print(type(v_chl_avg))
print(v_chl_avg.shape)
print(e_v_dates.shape)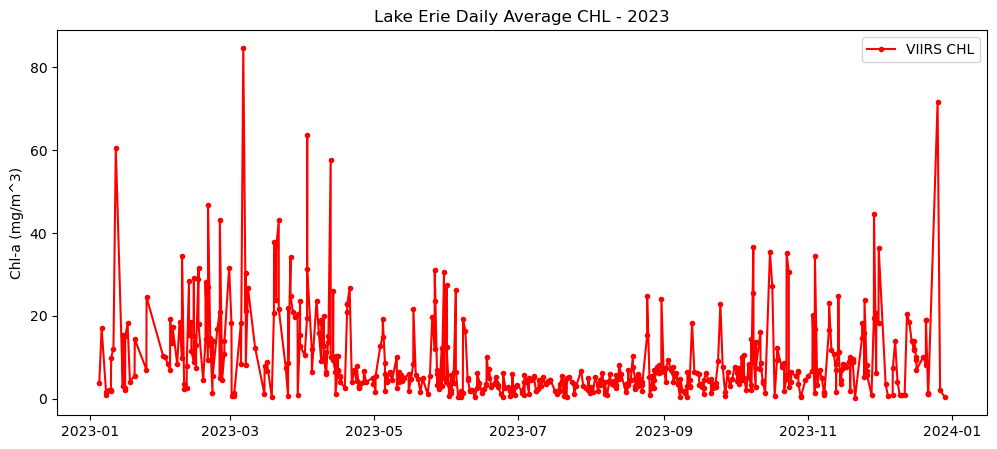
#e_v_ds.close()
!jupyter nbconvert --to html GL_python_tutorial2.ipynb