from IPython.display import clear_output
import pandas as pd
import numpy as np
import os
import warnings
import cartopy.crs as ccrs
import cartopy.feature as cfeature
from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter
from cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER
import matplotlib.pyplot as plt
import xarray as xr
warnings.filterwarnings('ignore')Matchup satellite data to ship, glider, or animal tracks
Overview
History | Updated Feb 2026
In this exercise you will extract satellite data around a set of points defined by longitude, latitude, and time coordinates, like that produced by an animal telemetry tag, and ship track, or a glider tract.
Please note that there may be more efficient ways, more Pythonic ways, to accomplish the tasks in this tutorial. The tutorial was developed to be easier to follow for less experienced users of Python.
The exercise demonstrates the following techniques:
- Loading data from a tab- or comma-separated file
- Plotting the latitude/longitude points onto a map
- Extracting satellite data along a track
- Summarizing satellite values using either a single nearest pixel or a small spatial window
- Saving results as a CSV file
- Plotting the satellite data onto a map
Datasets used:
- Chlorophyll a concentration from the European Space Agency’s Ocean Colour Climate Change Initiative Monthly dataset v6.0
- A loggerhead turtle telemetry track that has been subsample to reduce the data requests needed for this tutorial from over 1200 to 25. The turtle was raised in captivity in Japan, then tagged and released on 05/04/2005 in the Central Pacific. Its tag transmitted for over 3 years and went all the way to the Southern tip of Baja California. The track data can be downloaded from
datafolder in this project folder. - Dusky shark telemetry detections, consisting of longitude, latitude, date, and transmitter ID information from acoustic tags deployed along the U.S. East Coast. This example demonstrates matching satellite chlorophyll using a small spatial window (±0.2°) to better represent local environmental conditions experienced by the animal.
- Chlorophyll-a, Aqua MODIS, NPP, L3SMI, Global, 4km, Science Quality, 2003-present (8 Day Composite)
Python packages used:
- pandas (reading and analyzing data)
- numpy (data analysis, manipulation)
- xarray (multi-dimensional data analysis, manipulation)
- matplotlib (mapping)
- cartopy (mapping)
- datetime (date manipulation)
Import the required Python modules
Load the track data into a Pandas data frame
Below, the track data will load using the Pandas “read_csv” method. * Then use the “.head()” method to view the column names and the first few rows of data.
track_path = os.path.join('..',
'data',
'25317_05_subsampled.dat')
df = pd.read_csv(track_path)
print(df.head(2))Plot the track on a map
plt.figure(figsize=(14, 10))
# Label axes of a Plate Carree projection with a central longitude of 180:
ax1 = plt.subplot(211, projection=ccrs.PlateCarree(central_longitude=180))
# Use the lon and lat ranges to set the extent of the map
# the 120, 260 lon range will show the whole Pacific
# the 15, 55 lat range with capture the range of the data
ax1.set_extent([120, 260, 15, 55], ccrs.PlateCarree())
# Set the tick marks to be slightly inside the map extents
ax1.set_xticks(range(125, 255, 20), crs=ccrs.PlateCarree())
ax1.set_yticks(range(20, 60, 10), crs=ccrs.PlateCarree())
# Add feature to the map
ax1.add_feature(cfeature.LAND, facecolor='0.6')
ax1.coastlines()
# Format the lat and lon axis labels
lon_formatter = LongitudeFormatter(zero_direction_label=True)
lat_formatter = LatitudeFormatter()
ax1.xaxis.set_major_formatter(lon_formatter)
ax1.yaxis.set_major_formatter(lat_formatter)
# Bring the lon and lat data into a numpy array
x, y = df.mean_lon.to_numpy(), df.mean_lat.to_numpy()
ax1 = plt.plot(x, y, transform=ccrs.PlateCarree(), color='k')
# start point in green star
ax1 = plt.plot(x[0], y[0],
marker='*',
color='g',
transform=ccrs.PlateCarree(),
markersize=10)
# end point in red X
ax1 = plt.plot(x[-1], y[-1],
marker='X',
color='r',
transform=ccrs.PlateCarree(),
markersize=10)
plt.title('Animal Track for Turtle #25317', fontsize=20)
plt.show()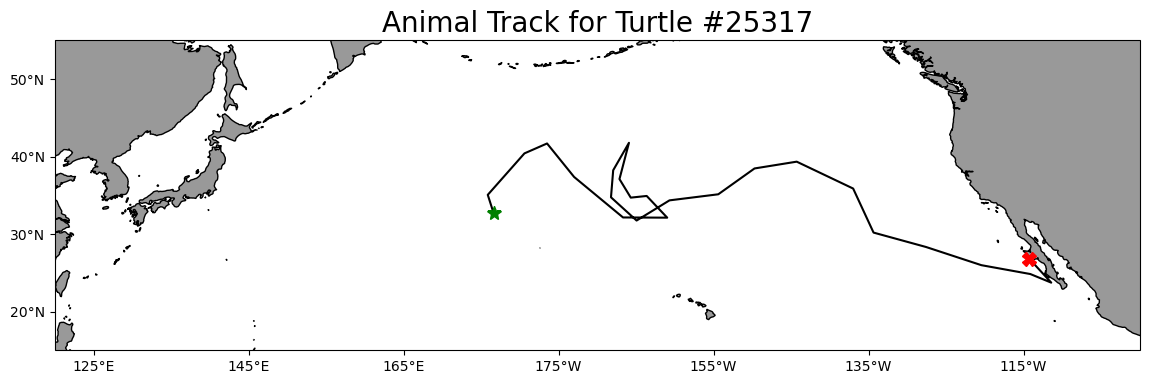
Prepare track data for use to extract satellite data
Create a column with Pandas date objects
Reload the “25317_05_subsampled.dat”. This time we will use the “parse_dates” option to create a Pandas date object column (year_month_day) from the ‘year’, ‘month’, and ‘day’ columns.
df = pd.read_csv(track_path,
parse_dates=[['year', 'month', 'day']]
)
print('The new year_month_day column contains the Pandas date objects')
print(df.head(2))
print(df.dtypes)Extract data from a satellite dataset corresponding to points on the track
We are going to download data from an ERDDAP server using the following steps: * Select a dataset on an ERDDAP server * Open the dataset using the Xarray module * Loop though the track data and pull out the date, latitude and longitude coordinates from each row * Insert these coordinates into the Xarray open-dataset object to select and download the satellite data that corresponds to the coordinates. * Store the satellite data in a temporary Pandas data frame * Once all the satellite data has been added to the temporary data frame, merge it with the track data frame.
Select a dataset
We’ll use the European Space Agency’s OC-CCI product (https://climate.esa.int/en/projects/ocean-colour/) to obtain chlorophyll data. This is a merged product that blends data from many ocean color sensors to create a long time series (1997-present) with better spatial coverage than any single sensor.
Ideally we would use a daily dataset, selecting the day that corresponds to the track data date. However, chlorophyll measurements can have a lot of missing data, primarily due to cloud cover. To reduce data gaps and improve the likelihood of data for our matchups, we can use a dataset that combines all of the data from each month into the monthly average.
The ERDDAP URL to the monthly version of the OC-CCI product is below:
https://oceanwatch.pifsc.noaa.gov/erddap/griddap/esa-cci-chla-monthly-v6-0
Open the satellite data in Xarray
- Use the ERDDAP URL with no extension (e.g. without .html or .graph…). This is the OPeNDAP URL, which allows viewing the dataset metadata and, when you select the data you want, downloading the data.
- Use the Xarray “open_dataset” function then view the metadata
erddap_url = '/'.join(['https://oceanwatch.pifsc.noaa.gov',
'erddap',
'griddap',
'esa-cci-chla-monthly-v6-0'])
ds = xr.open_dataset(erddap_url)
dsOpening the dataset in Xarray lets you look at the dataset metadata.
* The metadata are listed above. * No data is downloaded until you request it.
From the metadata you can view: * The coordinates (time, latitude and longitude) that you will use to select the data to download. * A list of ten data variables. For this exercise, we want the “chlor_a” variable. If you want, you can find out about each variable with clicking the page icon to the right of each variable name.
A note on dataset selection
We have preselected the OC-CCI monthly dataset because we know it will work with this exercise. If you were selecting datasets on your own, you would want to check out the dataset to determine if its spatial and temporal coverages are suitable for your application.
You can find that information above by clicking the right arrow next to “Attribute”. Then look through the list to find: * ‘time_coverage_start’ and ‘time_coverage_end’: the time range * ‘geospatial_lat_min’ and ‘geospatial_lat_max’: the latitude range * ‘geospatial_lon_min’ and ‘geospatial_lon_max’: the longitude range
There are a lot of metadata attributes to look through. We can make it easier with a little code to print out the metadata of interest. Then compare these ranges to those found in your track data.
print('Temporal and spatial ranges of the satellite dataset')
print('time range', ds.attrs['time_coverage_start'],
ds.attrs['time_coverage_end'])
print('latitude range', ds.attrs['geospatial_lat_min'],
ds.attrs['geospatial_lat_max'])
print('longitude range', ds.attrs['geospatial_lon_min'],
ds.attrs['geospatial_lon_max'])
print(' ')
print('Temporal and spatial ranges of the track data')
print('time range', df.year_month_day.min(), df.year_month_day.max())
print('latitude range',
round(df.mean_lat.min(), 2), round(df.mean_lat.max(), 2))
print('longitude range',
round(df.mean_lon.min(), 2), round(df.mean_lon.max(), 2))Download the satellite data that corresponds to each track location
# Create a temporary Pandas data frame to hold the downloaded satellite data
col_names = ["erddap_date", "matched_lat", "matched_lon", "matched_chla"]
tot = pd.DataFrame(columns=col_names)
# Finish each URL and download
for i in range(0, len(df)):
clear_output(wait=True)
print(i+1, 'of', len(df))
# Crop the dataset to include data that corresponds to track locations
cropped_ds = ds['chlor_a'].sel(time=df.year_month_day[i],
latitude=df.mean_lat[i],
longitude=df.mean_lon[i],
method='nearest'
)
# Downloaded the data and add it to a new line in the tot data frame
tot.loc[len(tot.index)] = [cropped_ds.time.values,
np.round(cropped_ds.latitude.values, 5), # round 5 dec
np.round(cropped_ds.longitude.values, 5), # round 5 dec
np.round(cropped_ds.values, 2) # round 2 decimals
]
print(tot.loc[[len(tot)-1]])
tot.head(2)Consolidate the downloaded satellite data into the track data frame
df[['matched_lat',
'matched_lon',
'matched_chla',
'erddap_date']] = tot[['matched_lat',
'matched_lon',
'matched_chla',
'erddap_date']]
df.head(2)Save your work
df.to_csv('chl_matchup_turtle25327.csv', index=False, encoding='utf-8')Plot chlorophyll matchup data onto a map
First plot a histogram of the chlorophyll data
print('Range:', df.matched_chla.min(), df.matched_chla.max())
_ = df.matched_chla.hist(bins=40)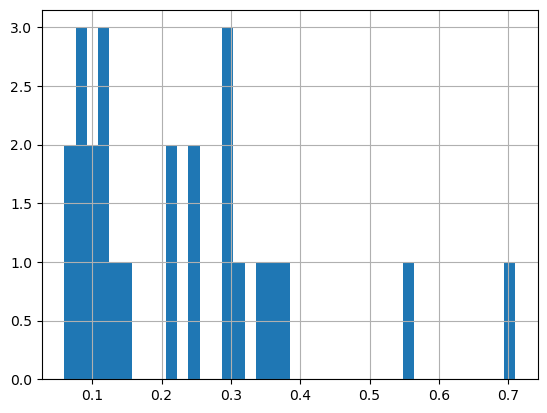
The range of chlorophyll values can be large, with lots of very low values and a few very high values. Using a linear color bar, most of the lower values would have the same color. * To better visualize the data, we often plot the log or log10 of chlorophyll.
Plot a histogram of the log of the chlorophyll data
print('Range:', np.log(df.matched_chla.min()), np.log(df.matched_chla.max()))
_ = np.log(df.matched_chla).hist(bins=40)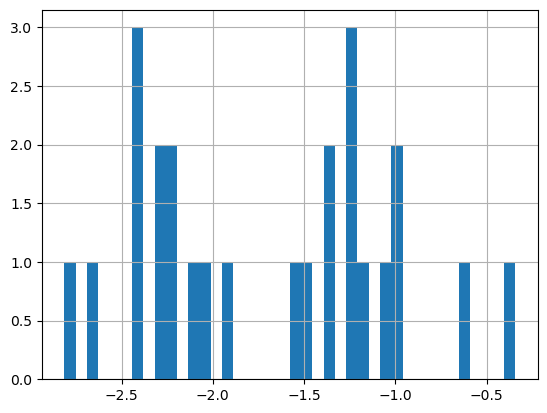
- The logarithmic transformation displays the range of values across the color bar range (above).
Map the chlorophyll data
plt.figure(figsize=(14, 10))
# Label axes of a Plate Carree projection with a central longitude of 180:
# set the projection
ax1 = plt.subplot(211, projection=ccrs.PlateCarree(central_longitude=180))
# Use the lon and lat ranges to set the extent of the map
# the 120, 260 lon range will show the whole Pacific
# the 15, 55 lat range with capture the range of the data
ax1.set_extent([120,255, 15, 55], ccrs.PlateCarree())
# set the tick marks to be slightly inside the map extents
ax1.set_xticks(range(120,255,20), crs=ccrs.PlateCarree())
ax1.set_yticks(range(20,50,10), crs=ccrs.PlateCarree())
# Add geographical features
ax1.add_feature(cfeature.LAND, facecolor='0.6')
ax1.coastlines()
# format the lat and lon axis labels
lon_formatter = LongitudeFormatter(zero_direction_label=True)
lat_formatter = LatitudeFormatter()
ax1.xaxis.set_major_formatter(lon_formatter)
ax1.yaxis.set_major_formatter(lat_formatter)
# build and plot coordinates onto map
x,y = list(df.mean_lon),list(df.mean_lat)
ax1 = plt.scatter(x, y, transform=ccrs.PlateCarree(),
marker='o',
c=np.log(df.matched_chla),
cmap=plt.get_cmap('jet')
)
ax1=plt.plot(x[0],y[0],marker='*', transform=ccrs.PlateCarree(), markersize=10)
ax1=plt.plot(x[-1],y[-1],marker='X', transform=ccrs.PlateCarree(), markersize=10)
# control color bar values spacing
levs2 = np.arange(-2.5, 0, 0.5)
cbar=plt.colorbar(ticks=levs2, shrink=0.75, aspect=10)
cbar.set_label("Chl a (mg/m^3)", size=15, labelpad=20)
# set the labels to be exp(levs2) so the label reflect values of chl-a, not log(chl-a)
cbar.ax.set_yticklabels(np.around(np.exp(levs2), 2), size=10)
plt.title("Chlorophyll Matchup to Animal Track #25317", size=15)
plt.show()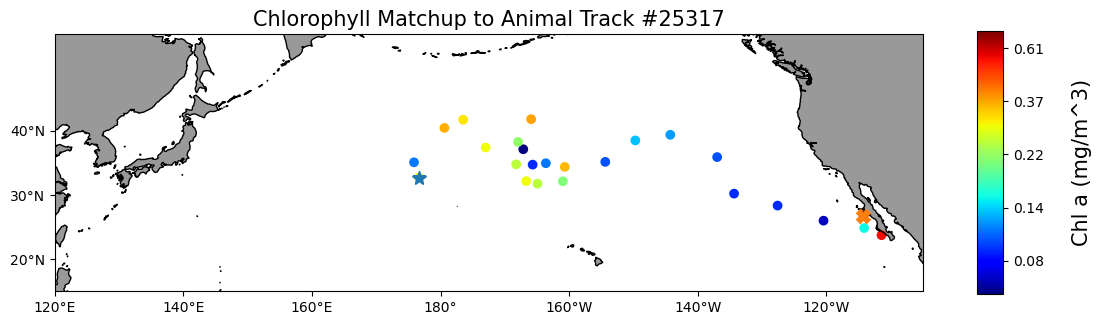
On your own!
Exercise 1:
Repeat the steps above with a different dataset. For example, extract sea surface temperature data using the NOAA Geo-polar Blended Analysis SST, GHRSST dataset: https://coastwatch.pfeg.noaa.gov/erddap/griddap/nesdisGeoPolarSSTN5NRT_Lon0360.html
* This dataset is a different ERDDAP; It has a different base URL and dataset ID and variable name. * Check the metadata to make sure the dataset covers the spatial and temporal range of the track dataset.
Exercise 2:
Go to an ERDDAP of your choice, find a dataset of interest, generate the URL, copy it and edit the script above to run a match up on that dataset. To find other ERDDAP servers, you can use this search engine: http://erddap.com/
* This dataset will likely be on a different base URL and dataset ID and variable name. * Check the metadata to make sure the dataset covers the spatial and temporal range of the track dataset.
Optional
Repeat the steps above with a daily version of the OC-CCI dataset to see how cloud cover can reduce the data you retrieve. https://oceanwatch.pifsc.noaa.gov/erddap/griddap/CRW_sst_v1_0.html
Match satellite chlorophyll to Dusky shark telemetry
The turtle example above selects a single nearest satellite pixel at each track point. In many real-world applications, it can be useful to match a small neighborhood of pixels around each location and summarize the satellite values (e.g. mean chlorophyll with ±0.2°). This helps reduce noise from single-pixel values and can better represent local conditions.
In this example, we:
- Load dusky shark tag detections (lon, lat, date)
- Open a gridded chlorophyll dataset using Xarray (OPenDAP)
- For each detection:
- select the nearest satellite time
- extract ±0.2° window in lon/lat
- compute mean, standard deviation, and valid pixel count
Data note: These dusky shark data were collected and provided by Dr. Chuck Bangley (Smithsonian Environmental Research Center). For details, see:
Bangley, C.W., et al. (2020) Identifying Important Juvenile Dusky Shark Habitat in the Northwest Atlantic Ocean Using Acoustic Telemetry and Spatial Modeling. Marine and Coastal Fisheries, 12:348–363. DOI: 10.1002/mcf2.10120Load Dusky shark telemetry data
Load the dusky shark acoustic telemetry detections, which include longitude, latitude, detection date, and transmitter ID. Each row represents a single shark detection that will be matched to satellite data.
# Load shark tag data (lon, lat, date, transmitter ID)
tag_path = os.path.join('..',
'resources',
'DuskyDaily_NOAAclass_sortedTransmitterDate.csv')
tags = pd.read_csv(tag_path)
print(tags.head(3))Convert telemetry columns to coordinate arrays
Longitude, latitude, and detection dates are extracted and converted into NumPy arrays and datetime objects. This format is required for iterating over detections and selecting satellite data by time.
# Convert columns to arrays (same pattern used earlier in this tutorial)
xcoord = tags["Longitude"].to_numpy()
ycoord = tags["Latitude"].to_numpy()
tcoord = pd.to_datetime(tags["Date"], format="%m/%d/%Y").to_numpy()Open a satellite dataset using Xarray (OPeNDAP)
For this example, we use a CoastWatch MODIS 8-day chlorophyll dataset
erddap_url2 = '/'.join(['https://coastwatch.pfeg.noaa.gov/',
'erddap',
'griddap',
'erdMH1chla8day'])
ds_shark = xr.open_dataset(erddap_url2)
ds_shark
print("Temporal and spatial ranges of the satellite dataset")
print("time range", ds_shark.attrs["time_coverage_start"], ds_shark.attrs["time_coverage_end"])
print("latitude range", ds_shark.attrs["geospatial_lat_min"], ds_shark.attrs["geospatial_lat_max"])
print("longitude range", ds_shark.attrs["geospatial_lon_min"], ds_shark.attrs["geospatial_lon_max"])Match each shark detection to a local satellite window (±0.2°)
This function matches a single shark detection to satellite chlorophyll by selecting the nearest satellite time and extracting a ±0.2° spatial window. It summarizes local conditions by computing the mean, standard deviation, and number of valid pixels.
def match_one_point(ds, lon, lat, req_time, half_window=0.2):
"""
Match a single telemetry detection to satellite chlorophyll using
spatial averaging within a local window.
For a given longitude, latitude, and detection time, this function:
selects the nearest satellite time, extracts chlorophyll pixels within
a ±half_window degree box around the detection, and summarizes local
conditions using the mean, standard deviation, and number of valid pixels.
Parameters
----------
ds : xarray.Dataset
ERDDAP gridded satellite dataset opened via Xarray/OPeNDAP.
lon : float
Longitude of the telemetry detection (decimal degrees).
lat : float
Latitude of the telemetry detection (decimal degrees).
req_time : datetime-like
Telemetry detection time; the nearest satellite time is used.
half_window : float, optional
Half-width of the spatial averaging window in degrees (default 0.2).
Returns
-------
dict
Dictionary containing mean chlorophyll, standard deviation, number
of valid pixels, the matched satellite time, spatial window bounds,
and the original detection time.
"""
# Nearest satellite time
ds_time = ds.sel(time=req_time, method="nearest")
sat_time = pd.to_datetime(ds_time.time.values)
# Spatial bounds
lon_min = lon - half_window
lon_max = lon + half_window
lat_min = lat - half_window
lat_max = lat + half_window
# Latitude often runs descending in ERDDAP products
chl = ds_time["chlorophyll"].sel(
longitude=slice(lon_min, lon_max),
latitude=slice(lat_max, lat_min)
)
return {
"mean_chlorophyll": float(chl.mean(skipna=True)),
"stdev_chlorophyll": float(chl.std(skipna=True)),
"n": int(chl.count()),
"satellite_date": sat_time,
"requested_lon_min": lon_min,
"requested_lon_max": lon_max,
"requested_lat_min": lat_min,
"requested_lat_max": lat_max,
"requested_date": pd.to_datetime(req_time),
}Run the matchup for all shark detections
# Run the matchup for every point:
half_window = 0.2
rows = [
match_one_point(ds_shark, lon, lat, t, half_window=half_window)
for lon, lat, t in zip(xcoord, ycoord, tcoord)
]
shark_matchups = pd.DataFrame.from_records(rows)
shark_matchups.head()Assemble a consolidated telemetry–satellite dataset
Telemetry coordinates, transmitter IDs, and matched chlorophyll values are combined into a single DataFrame. This unified table is used for all subsequent mapping and analysis steps.
alltags = pd.DataFrame({
"lon": xcoord,
"lat": ycoord,
"chlorophyll": shark_matchups["mean_chlorophyll"].to_numpy(),
"transmitter": tags["Transmitter"].to_numpy(),
"date": shark_matchups["requested_date"].to_numpy(),
})
print(alltags.shape)
alltags.head()Map of all sharks colored by chlorophyll
Plot the locations of all tagged dusky sharks and color each detection by the mean satellite-derived chlorophyll-a concentration matched to that location and date.
Each point represents a single shark detection, and the color scale highlights spatial differences in chlorophyll conditions encountered by sharks across the study area. A simple land mask and coastline provide geographic context, while latitude and longitude gridlines help orient the map.
This visualization provides a spatial overview of shark movements in relation to surface ocean productivity.
fig = plt.figure(figsize=(8, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.add_feature(cfeature.LAND, facecolor="lightgray")
ax.add_feature(cfeature.COASTLINE)
sc = ax.scatter(
alltags["lon"],
alltags["lat"],
c=alltags["chlorophyll"],
cmap="YlGn",
s=20,
transform=ccrs.PlateCarree()
)
plt.colorbar(sc, label="Chl-a (mg m$^{-3}$)")
gl = ax.gridlines(
draw_labels=True,
linewidth=0.5,
color="gray",
alpha=0.7,
linestyle="--"
)
gl.top_labels = False
gl.right_labels = False
gl.xformatter = LONGITUDE_FORMATTER
gl.yformatter = LATITUDE_FORMATTER
ax.set_title("Mean chlorophyll at dusky shark locations")
plt.show()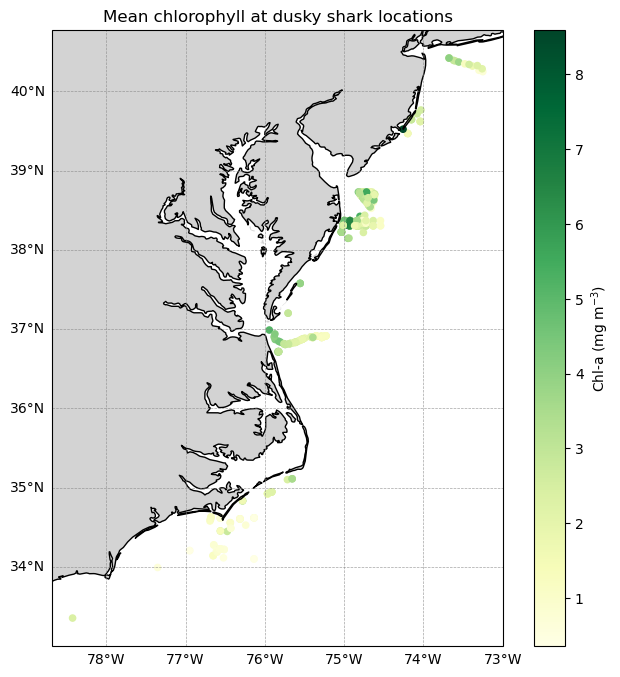
Plot the movement track for a single shark
Successive detections for one shark are connected with track lines and colored by chlorophyll concentration. This combined view highlights both movement pathways and changing environmental conditions along the track.
x = single_shark["x_shark"].to_numpy()
y = single_shark["y_shark"].to_numpy()
chl = single_shark["dataval_shark"].to_numpy()
pad = 0.5
maplonmin = x.min() - pad
maplonmax = x.max() + pad
maplatmin = y.min() - pad
maplatmax = y.max() + pad
fig = plt.figure(figsize=(6, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.add_feature(cfeature.LAND, facecolor="lightgrey")
ax.add_feature(cfeature.COASTLINE)
ax.set_extent([maplonmin, maplonmax, maplatmin, maplatmax], crs=ccrs.PlateCarree())
# Track polyline
ax.plot(
x, y,
color="black",
linewidth=1,
alpha=0.7,
transform=ccrs.PlateCarree()
)
# Scatter points
sc = ax.scatter(
x, y,
c=chl,
cmap="YlGn",
s=25,
transform=ccrs.PlateCarree(),
zorder=3
)
gl = ax.gridlines(draw_labels=True, linewidth=0.5, color="gray", alpha=0.7, linestyle="--")
gl.top_labels = False
gl.right_labels = False
gl.xformatter = LONGITUDE_FORMATTER
gl.yformatter = LATITUDE_FORMATTER
gl.xlabel_style = {"size": 9}
gl.ylabel_style = {"size": 9}
cbar = plt.colorbar(sc, ax=ax)
cbar.set_label("Chl-a (mg m$^{-3}$)")
ax.set_title("Mean chl-a values for dusky shark #1 (with tracks)")
plt.show()
plt.close(fig)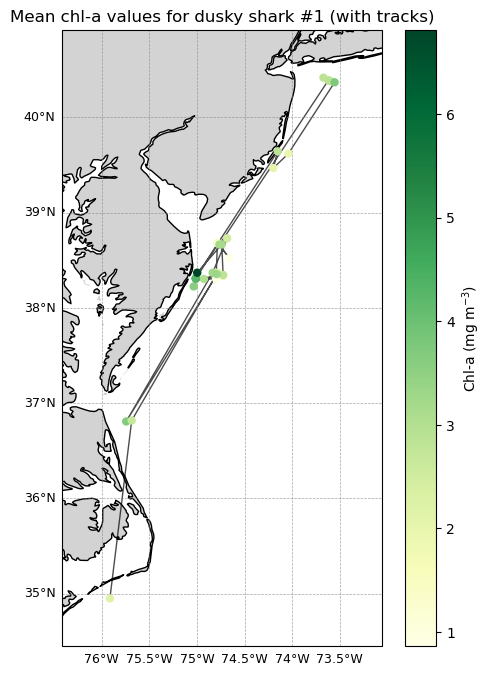
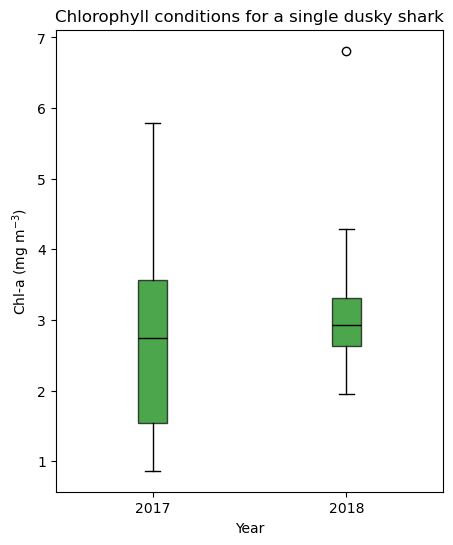
Compare chlorophyll conditions by year using a boxplot
Matched chlorophyll values for a single shark are grouped by calendar year and displayed as a boxplot. The boxplot summarizes interannual differences and variability in environmental conditions experienced by the shark.
df1 = alltags.loc[alltags["transmitter"] == shark1, ["date", "chlorophyll"]].dropna()
df1["year"] = pd.to_datetime(df1["date"]).dt.year
vals_2017 = df1.loc[df1["year"] == 2017, "chlorophyll"].to_numpy()
vals_2018 = df1.loc[df1["year"] == 2018, "chlorophyll"].to_numpy()
fig, ax = plt.subplots(figsize=(5, 6))
ax.boxplot(
[vals_2017, vals_2018],
positions=[1, 2],
patch_artist=True, # allow filled boxes
boxprops=dict(facecolor="green", alpha=0.7),
medianprops=dict(color="black"),
whiskerprops=dict(color="black"),
capprops=dict(color="black")
)
ax.set_title("Chlorophyll conditions for a single dusky shark")
ax.set_xlabel("Year")
ax.set_ylabel("Chl-a (mg m$^{-3}$)")
ax.set_xticks([1, 2])
ax.set_xticklabels(["2017", "2018"])
plt.show()